📝 Publications
* indicates equal contribution.
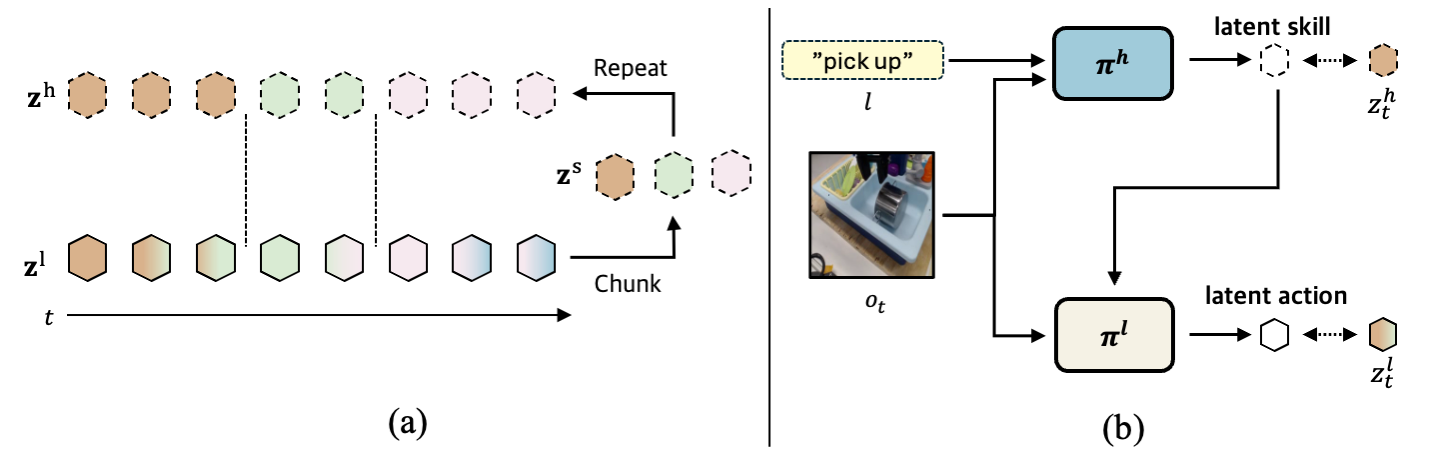
Hierarchical Latent Action Model
Hanjung Kim, Lerrel Pinto, Seon Joo Kim
ICLRW 2026 2nd Workshop on World Models: Understanding, Modelling and Scaling
[Paper]
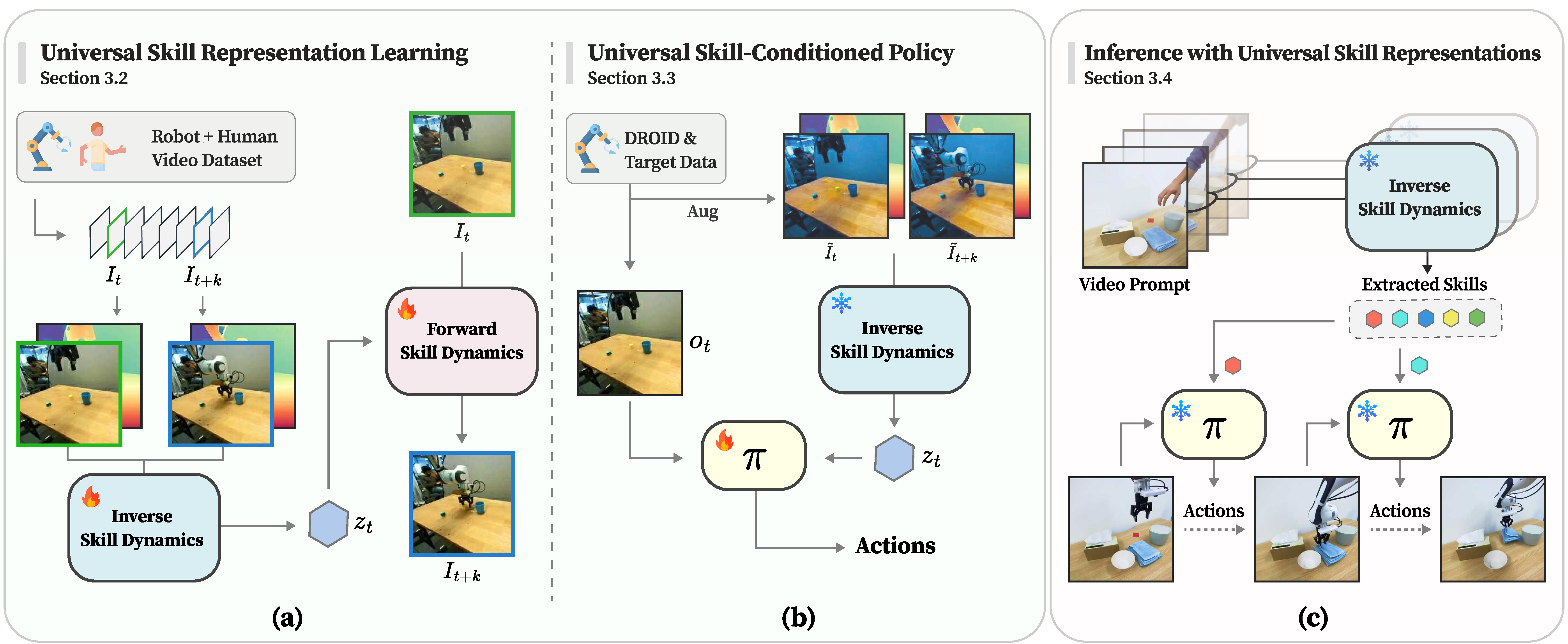
UniSkill: Imitating Human Videos via Cross-Embodiment Skill Representations
Hanjung Kim$^*$, Jaehyun Kang$^*$, Hyolim Kang, Meedeum Cho, Seon Joo Kim, Youngwoon Lee
CoRL 2025
[Project] [Paper] [Code]
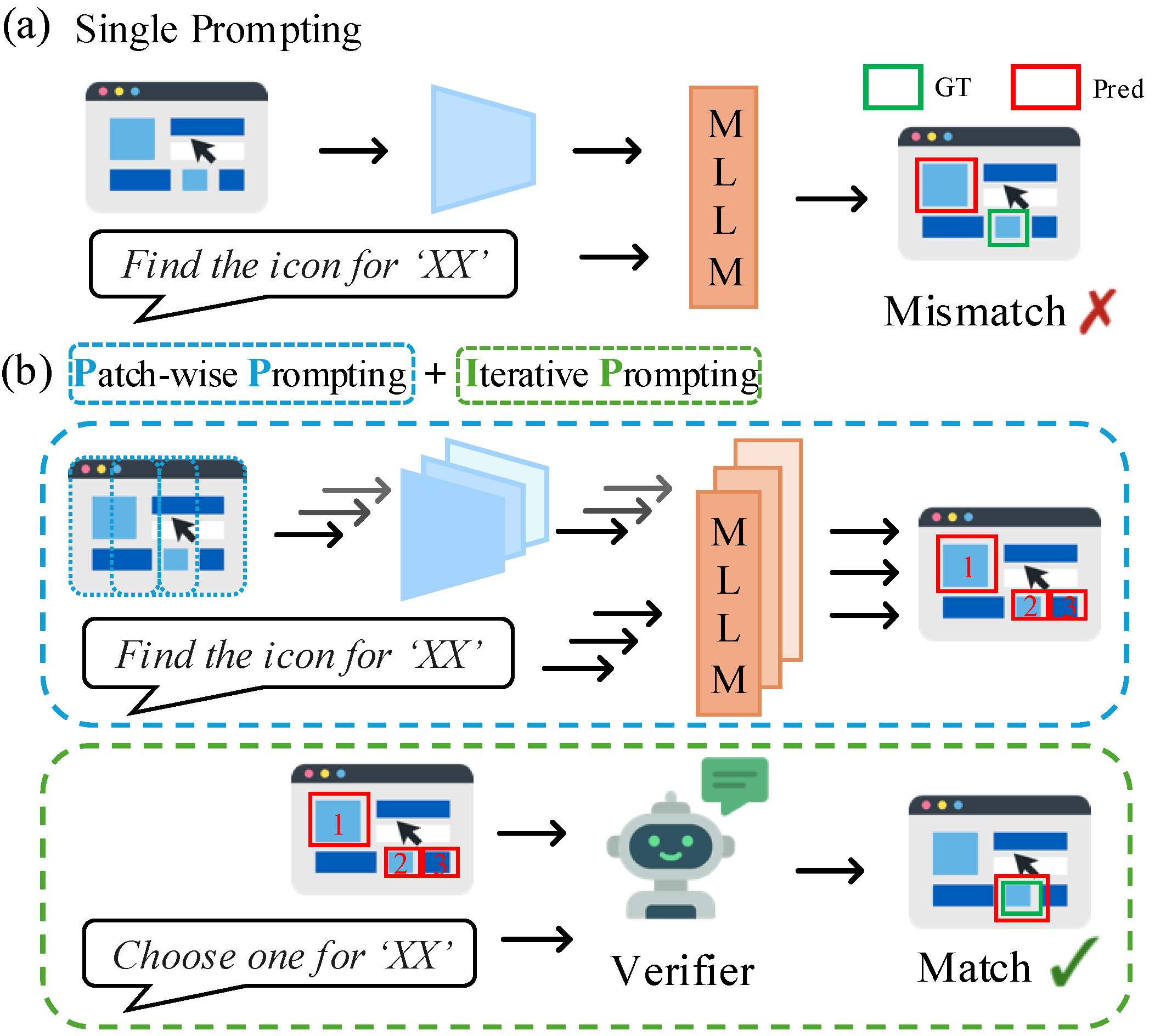
A Training-Free, Task-Agnostic Framework for Enhancing MLLM Performance on High-Resolution Images
Jaeseong Lee$^*$, Yeeun Choi$^*$, Heechan Choi$^*$, Hanjung Kim, Seon Joo Kim
CVPRW 2025 2nd Workshop on Emergent Visual Abilities and Limits of Foundation Models Workshop
[Paper]
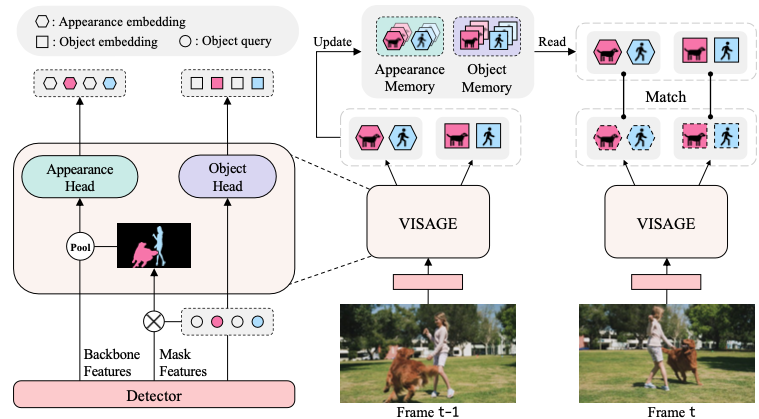
VISAGE: Video Instance Segmentation with Appearance-Guided Enhancement
Hanjung Kim, Jaehyun Kang, Miran Heo, Sukjun Hwang, Seoung Wug Oh, Seon Joo Kim
ECCV 2024
[Project] [Paper] [Code]
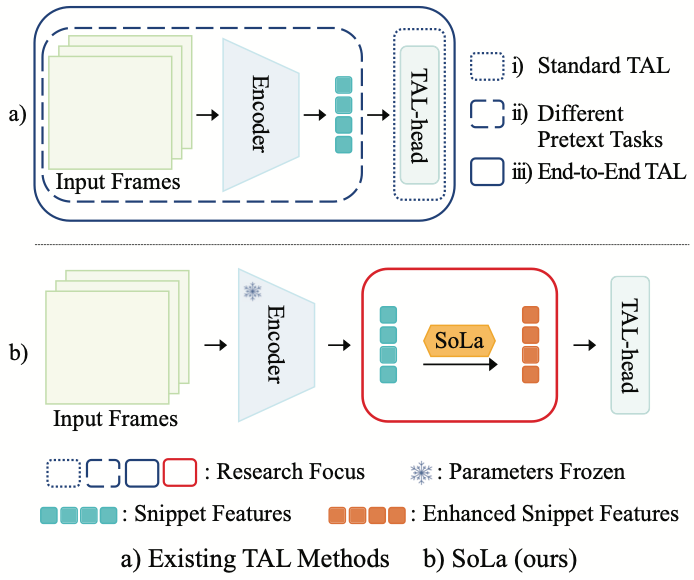
Soft-Landing Strategy for Alleviating the Task Discrepancy Problem in Temporal Action Localization Tasks
Hyolim Kang, Hanjung Kim, Joungbin An, Minsu Cho, Seon Joo Kim
CVPR 2023 Finalist at Qualcomm Innovation Fellowship 2023
[Paper] [Code]
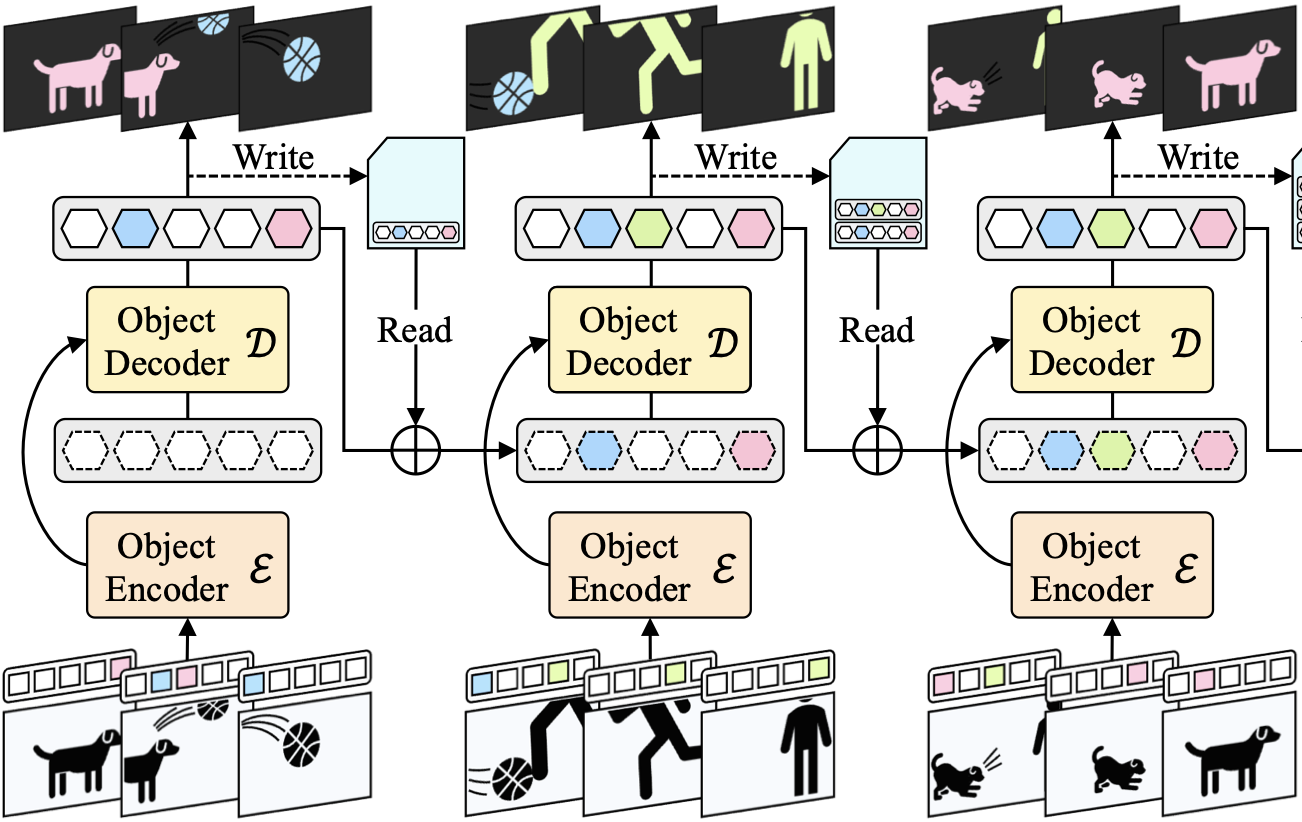
A Generalized Framework for Video Instance Segmentation
Miran Heo, Sukjun Hwang, Jeongseok Hyun, Hanjung Kim, Seoung Wug Oh, Joon-Young Lee, Seon Joo Kim
CVPR 2023
[Paper] [Code]